고정 헤더 영역
상세 컨텐츠
본문

LLM 기초
LLM은 많은 스마트폰이 제공하는 자동 완성 기능과 유사하게 동작한다. 텍스트를 입력 받아 다음 텍스트 출력을 예측하고 생성하는 훈련된 알고리즘이다.
LLM의 예측력을 좌우하는 핵심은 트랜스포머 신경망 아키텍처이다.
트랜스포머 구조는 문장이나 코드 등 데이터의 연속체를 처리하며, 연속체에서 가장 가능성이 높은 다음 단어를 예측한다. 트랜스포머는 문장 내의 각 단어와 다른 모든 다언의 관계를 고려해 문맥을 파악한다. 이 방법을 통해 LLM은 문장이나 단락 등이 서로 연결되어 나타내는 의미를 포괄적으로 이해한다.
프롬프트 엔지니어링
사고의 연쇄(CoT)
LLM의 성능을 높이는 좋은 방법은 LLM이 시간을 들여 사고하도록 추가 지시하는 것이다.
이른바 사고의 연쇄 (Chain-of-Thought) 라고 부르는 프롬프트 기법은 프롬프트 앞에 LLM이 답에 도달하는 과정을 설명하도록 지시문을 삽입한다.
예를 들어 프롬프트 앞에 "단계별로 생각해"와 같은 지시문을 붙여서 llm이 답을 추론할때 단계적으로 생각할 수 있도록 한다. 그러나 CoT는 직관적인 생각이 더 빠른 경우(사진을 보고 고양이라고 생각하는 등)에는 비효율적인 프롬프팅 기법이다.
검색 증강 생성(RAG)
검색 증강 생성 (Retrieval-Augmented Generation)은 관련 있는 텍스트 조각을 찾아내, 해당 텍스트 조각을 컨텍스트라 칭하며 프롬프트에 포함한다.
퓨샷 프롬프트
LLM에게 질문과 정답의 예제를 몇 가지 제공하여, 추가적인 훈련이나 파인튜닝을 거치지 않고도 새로운 작업을 수행하는 방법을 익히게 한다. 파인튜닝을 하기 전에 보통은 항상 퓨샷 프롬프트를 시도한다.
랭체인 기초
Message
- LLM에게 넣어주는 프롬프트
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai.chat_models import ChatOpenAI
model = ChatOpenAI()
system_msg = SystemMessage(
'''당신은 문장 끝에 느낌표를 세 개 붙여 대답하는 친절한 어시스턴트입니다.'''
)
human_msg = HumanMessage('프랑스의 수도는 어디인가요?')
response = model.invoke([system_msg, human_msg])
print(response.content)- HumanMessage : 사용자 역할인 인간의 관점으로 작성한 메세지
- AIMessage : 어시스턴트 역할인 AI의 관점으로 작성한 메세지
- SystemMessage : 시스템 역할인 AI가 준수할 지침을 설정하는 메세지
- ChatMessage : 임의의 역할을 설정하는 메세지
JOSN 출력
- LLM이 출력할 JSON의 스키마를 정의
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
class AnswerWithJustification(BaseModel):
'''사용자의 질문에 대한 답변과 그에 대한 근거(justification)를 함께 제공하세요.'''
answer: str
'''사용자의 질문에 대한 답변'''
justification: str
'''답변에 대한 근거'''
llm = ChatOpenAI(model='gpt-4o-mini', temperature=0)
structured_llm = llm.with_structured_output(AnswerWithJustification)
result = structured_llm.invoke('''1 킬로그램의 벽돌과 1 킬로그램의 깃털 중 어느 쪽이 더 무겁나요?''')
print(result.model_dump_json())- with_structured_output() 함수를 통해 랭체인은 AnswerWithJstification 객체를 JSONSchema 객체로 변환해 LLMdp 전송한다. 랭체인은 LLM에서 이를 수행할 최선의 방법을 선택한다. 주로 함수호출과 프롬프트 작성에 많이 쓰인다.
- LLM이 반환한 출력물을 반환하기전에 그 유효성을 검증하고 이를 통해 출력 결과가 스키마를 정확히 준수하는지 확인한다.
Runnable
- invoke
- ainvoke
- stream
- batch
랭체인은 llm을 호출하기 위해 위 4개의 함수를 제공한다. Runnable 객체는 통일된 인터페이스를 제공하여 위 4개의 함수를 모두 사용할 수 있게 해준다.
@chain
def chatbot(values):
prompt = template.invoke(values)
return model.invoke(prompt)- 위 함수의 chain 데코레이션은 Runnable 인터페이스를 추가해주는데 내부적으로 @chain 데코레이션은 함수를 RunnableLambda 객체로 감싸주는 역할을 한다.
- RunnableLambda 객체는 Runnable을 상속받아 모든 Runnable 메서드를 구현함
RAG
데이터 인덱싱
- RAG를 진행하기전 데이터 전처리 단계이다.
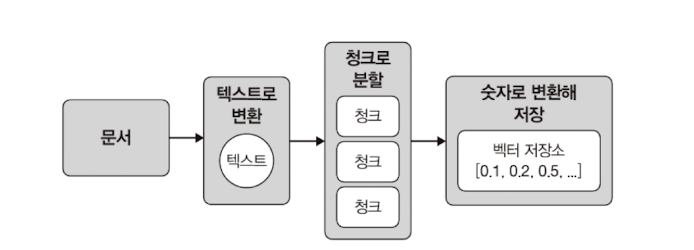
- 문서에서 텍스트를 추출하여 효율적으로 처리하기 위해 청킹을 진행하고, 텍스트를 컴퓨터가 이해할 수 있는 숫자 체계로 인코딩한다. 마지막으로 텍스트의 숫자 표현을 vector db의 적절한 위치에 저장한다.
- 위 과정을 인제스천(ingestion) 이라고 부르며 숫자 데이터는 임베딩(embedding)이라 부르고 특수한 유형의 데이터베이스를 벡터 저장소라고 부른다.
의미론적 임베딩
- LLM 이전의 임베딩은 나오는 단어가 비슷한 문장끼리만 비슷하다고 판단이 되었다. 즉 "날씨 좋다."와 "하늘 참 푸르다."는 의미론적으론 비슷한 문장이지만 겹치는 단어가 없기에 LLM 이전의 임베딩에서는 두 문장이 비슷하지 않다고 판단했다.
그러나 LLM이 단어의 의미를 파악하고 LLM을 이용한 임베딩 모델들이 나오면서 의미론적으로 임베딩이 가능해졌다.
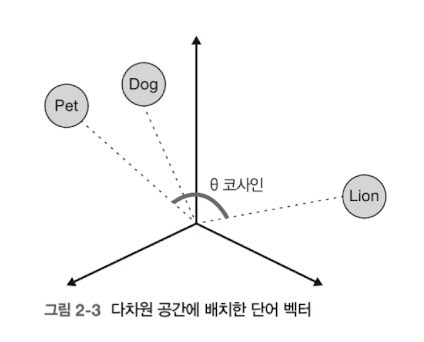
- 먼저 단어를 컴퓨터가 사용하는 언어인 숫자로 변환하고, 각 단어와 이에 상응하는 의미론적 임베딩(숫자 데이터)이 나란히 배치된다. 숫자 자체는 특별한 의미를 갖지 않으므로, 의미 유사성이 높은 단어나 문장을 표현하는 숫자 배열은 관련성이 없는 경우보다 '가깝게' 구성된다. 가깝게의 의미는 위 그림에서 볼 수 있다.
Pet과 Dog가 Pet과 Lion보다 더 가깝게 배치되어 있다. LLM은 이 가까운 거리를 코사인 유사도를 통해 계산한다. Pet과 Lion사이의 각도가 Pet과 Dog 사이의 각도보다 커서 Pet과 Dog가 더 유사함을 알 수 있다.
Vetor 임베딩을 위한 랭체인 제공 툴
WebBaseLoader
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader('https://www.langchain.com/')
docs = loader.load()
print(docs)- URL로 접근하여 그 페이지의 데이터를 긁어 온다.
RecursiveCharacterTextSplitter
- 대량의 문서를 의미 있는 소규모 텍스트 단위(청크)로 손쉽게 분할가능
- 중요도에 따라 구분자 목록을 작성
- 문단 구분자 : \n\n
- 줄 구분자 : \n
- 단어 구분자 : 공백 문자
- 제한된 청크(예: 1000자)를 만족하도록 단락을 분할하는 작업 진행
- 먼저 문단 구분자인 \n\n으로 나눔
- 청크의 허용 크기를 초과하는 단락은 이후에 등장하는 구분자(줄 바꿈)를 기준으로 분할, 모든 청크가 목표 길이보다 작아지거나 적용할 추가 구분자가 없을 때까지 이 과정 반복
- 실패한 청크를 다음 구분자인 \n(줄바꿈)으로 나눔
- 또 제한된 청크를 넘어선다면 공백 문자를 기준으로 나눔
- 각 청크는 Document 형식으로 출력하며, 원본 문서의 메타데이터와 원본 문서에서의 위치에 관한 추가 정보 제공
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import (
Language,
RecursiveCharacterTextSplitter,
)
loader = WebBaseLoader('https://namu.wiki/w/%EC%9E%90%ED%8F%90%EC%84%B1%20%EC%9E%A5%EC%95%A0')
docs = loader.load()
# print(docs)
print(docs[0].page_content)
for i in range(10, docs) :
print(f"=== Document {i+1} ===")
print(docs[i])
print("=" * 50)
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splitted_docs = splitter.split_documents(docs)
for i in range(min(10, len(splitted_docs))):
print(f"=== Document {i+1} ===")
print(splitted_docs[i])
print("=" * 50)- 위 코드를 보면 처음 webBaseLoader() 가져온 대량의 텍스트를 RecursiveCharacterTextSplitter()로 나누는 코드이다.
- chunk_size는 각 텍스트 조각의 최대치이다.
- chunk_overlap은 앞 뒤 청크와 몇 자씩 중복될 것인가이다.
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)- 또한 fromLanguage() 함수들 통해서 python, 마크다운, 자바스크립트 등 프로그래밍 언어도 분할 가능하다.
인덱싱 최적화
MultiVectorRetriever
- 요약본을 만들어 검색시에 요약본 먼저 확인하고 원본을 가져오는 방식
- 복잡하고 긴 문서 기반의 RAG(검색 증강 생성) 시스템을 구축할 때 효율적
# =============== 1 =================== #
prompt = ChatPromptTemplate.from_template(prompt_text)
llm = ChatOpenAI(temperature=0, model='gpt-4o-mini')
summarize_chain = {
'doc': lambda x: x.page_content} | prompt | llm | StrOutputParser()
summaries = summarize_chain.batch(chunks, {'max_concurrency': 5})
# =============== 2 =================== #
# 벡터 저장소는 하위 청크를 인덱싱하는 데 사용
vectorstore = PGVector(
embeddings=embeddings_model,
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# =============== 3 =================== #
doc_ids = [str(uuid.uuid4()) for _ in chunks]
# =============== 4 =================== #
# 각 요약은 doc_id를 통해 원본 문서와 연결
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
retriever.vectorstore.add_documents(summary_docs)
# =============== 5 =================== #
sub_docs = retriever.vectorstore.similarity_search(
'chapter on philosophy', k=2)- 먼저 체인을 생성하여 chunks라는 데이터를 llm에 입력된 프롬프트를 적용하여 요약하고 체인을 실행한다.
- RecusiveCharacterTextSplitter 객체의 split_documents() 함수를 활용하여 document 객체로 만들었기에 .page_content로 각 데이터의 컨텐츠만 가져온다.
- 벡터 저장소를 생성하고, MultiVectorRetriever를 생성하여 요약본이 저장될 백터 저장소와 원본이 저장될 docstore를 id_key로 연결한다.
- 각 요약본의 원본을 찾아갈 수 있어야 하기에 split된 청크마다 uuid를 생성해준다.
- 요약본을 각 생성된 doc_id와 연결하여 변수를 만들고 그 변수를 위에서 생성한 vector 스토어에 임베딩한다.
- 검색을 진행하면 vector 스토어에서 요약본을 가져오고 그 id로 부터 원본 저장소에서 원본을 꺼내온다.
RAPTOR(Recursive abstractive processing for tree-organized retrieval)
라그 시스템은 단일 문서에 존재하는 특정 사실을 참조하는 하위 수준의 질문과 여러 문서에 걸쳐 산출된 아이디어를 도출하는 상위 수준의 질문을 모두 처리할 수 있어야 한다.
- 트리 형태 검색을 위한 재귀적 추상 처리
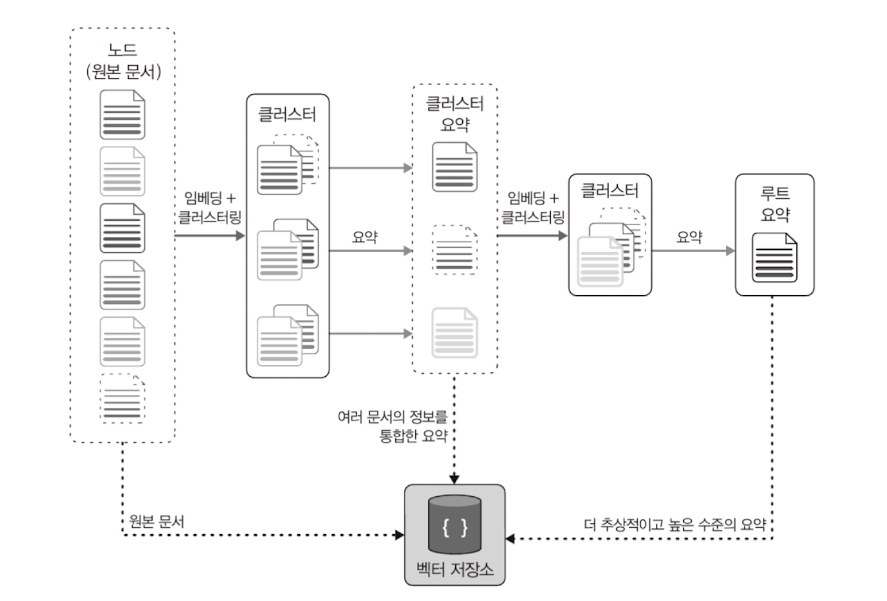
- 원본 문서들을 임베딩 하여 비슷한 구역에 있는 데이터들끼리 클러스터링(하나의 그룹으로 묶음)을 진행한다.
- 그렇게 묶인 그룹을 llm이 요약을 진행한다. -> 클러스터 요약
- 다시 한 번 생성된 요약문들을 재귀적으로 임베딩하고 또 클러스터링 하여 더 상위의 요약문을 계속 만들어 낸다.
ColBERT(Contextualized Late Interaction over BERT)
BERT
- Bidirectional Encoder Representations from Transformers 자연어 처리 언어 모델
- 이전 모델은 왼쪽에서 오른쪽으로만 읽으면서 문맥을 파악했지만 BERT는 문장의 앞뒤 문맥을 동시에 파악 가능
Bi-Encoder
- 두 개의 독립된 인코더를 사용해서 검색어와 문서를 각각 별도의 벡터로 변환함, 두 입력은 서로의 존재를 모르고 각자 의미만을 담은 벡터로 인코딩 됨
검색어 → 인코더 A → 검색어 벡터
문서 → 인코더 B → 문서 벡터
모든 문서를 미리 벡터로 저장해두고 검색 시에는 검색어만 벡터로 만들어서 두 개의 코사인 유사도를 비교하므로 매우 빠름
검색어와 문서가 서로의 문맥을 직접 비교하지 않고 독립적으로 해석된 결과를 나중에 비교하기에 정확도가 낮음
Cross-Encoder
- 하나의 인코더에 검색어와 문서를 한 쌍으로 함께 입력하여 두 텍스트가 서로에게 어떤 영향을 미치는지 처음부터 끝까지 상호작용하며 분석
[검색어 + 문서] → 하나의 인코더 → 유사도 점수 (0~1)
두 텍스트 간의 의미 관계까지 파악할 수 있어, 가장 관련성 높은 결과를 찾아내므로 정확도가 매우 높음
검색할 때마다 모든 문서 후보와 검색어를 일일이 쌍으로 묶어 모델에 넣어야 함, 즉 미리 계산해 둘 수 없기 때문에 매우 느림
ColBERT
- Bi-Encoder와 Cross-Encoder의 장점을 결합한 지연된 상호작용(Late Interaction) 아키텍처
문서 → 인코더 A → 모든 단어의 의미를 담은 문서 벡터
검색어 → 인코더 B → 모든 단어의 의미를 담은 검색어 벡터
검색어, 문서의 각 단어 벡터 비교
Bi-Encoder처럼 다른 인코더를 사용해서 문서를 미리 인코딩 해놓을 수 있어서 빠름
Cross-Encoder처럼 문서와 검색어를 단어 단위로 하나하나 비교해서 더 정확한 결과를 가져올 수 있음
문서와 검색어가 모두 독립적으로 인코딩 된 후에 나중에 서로를 비교하기 때문에 인코딩 전이나 인코딩 도중에 비교하는 이전 '조기 상호작용' 모델들 보다 빠름
'책 > 책 리뷰' 카테고리의 다른 글
| ⌈책 리뷰⌋ 메이오 오신 ⎹ 러닝 랭체인 ⎹ 2부 (1) | 2025.10.03 |
|---|---|
| ⌈책 리뷰⌋ 로버트 C. 마틴 ⎹ 클린 아키텍처 ⎹ ⭐️ (0) | 2025.09.15 |
| ⌈책 리뷰⌋ 찰스 두히그 ⎹ 습관의 힘 ⎹ ⭐️ (4) | 2025.07.29 |
| ⌈책 리뷰⌋ 제임스 클리어 ⎹ 아주 작은 습관의 힘 ⎹ (4) | 2025.07.08 |
| ⌈책 리뷰⌋ 미하이 칙센트미하이, ⎹ 몰입의 기술 ⎹ ⭐️ (0) | 2025.04.22 |




